Does technical SEO affect AI crawler access and citation rates?
Key findings
- 173% of websites have at least one technical barrier blocking AI crawler access: mostly misconfigured robots.txt, CDN blocks, and JavaScript rendering failures (OtterlyAI)
- 2ChatGPT, Claude, and Gemini parse static HTML only: client-side JavaScript pages take 9× longer to process; only Copilot renders full JavaScript (Writesonic; Search Engine Land)
- 3Descriptive URL slugs produce 89.78% ChatGPT citation rate vs 81.11% for non-descriptive: 8.67 percentage point difference (Ahrefs, 1.4 million prompts)

AI crawlability problems are mostly old technical SEO problems at a larger scale. Google states explicitly that the only prerequisite for AI Overviews eligibility is standard search indexing: no separate GEO configuration required. But a Writesonic analysis of 6 major AI crawlers found that ChatGPT, Claude, and Gemini parse static HTML only, while Copilot is the only platform that renders full JavaScript. Client-side JavaScript pages take 9× longer for AI crawlers to process than static HTML (Search Engine Land).
If your site renders key content via JavaScript, three of the four major AI platforms may not be reading it. The crawlability gap is not exotic: it is the same JavaScript rendering problem that has limited Google visibility for years, now affecting a broader set of crawlers with fewer resources to spend on each site.
What is AI crawlability and why does it matter for GEO?
AI crawlability refers to how accessible and parseable your site's content is to the crawler bots operated by AI search platforms: GPTBot and OAI-SearchBot (OpenAI), ClaudeBot (Anthropic), GoogleBot-Extended and Google-Agent (Google), Bingbot (Microsoft), and PerplexityBot (Perplexity). Each crawler operates independently: allowlisting GPTBot has no effect on ClaudeBot, and blocking one does not affect the others. A Duda analysis of 858,457 business locations found 59% received at least one AI crawler visit in February 2026, with 68.9 million total AI crawler visits recorded that month.
Crawlability for AI search operates at three layers. The first is access: whether your robots.txt allows AI crawlers and whether CDN or WAF rules are not accidentally blocking bot traffic. The second is rendering: whether your content is available as static HTML (readable by all AI crawlers) or requires JavaScript execution (only Copilot renders JavaScript fully; ChatGPT, Claude, and Gemini parse HTML only). The third is retrieval-layer eligibility: for platforms like Google AI Overviews and SearchGPT, eligibility is determined by your position in traditional search rankings, not by AI-crawler crawlability directly.
35 sources reviewed · High confidence (18.0/35)
Does technical SEO affect AI crawler access and citation rates?
Yes: but the ceiling on what crawlability fixes can achieve is determined by your position in traditional search, not by how many AI crawlers you've allowlisted.
Google's Search Central documentation states that to be eligible in AI Overviews, a page "must be indexed, meet standard Search technical requirements. No additional requirements." For platforms like Perplexity and ChatGPT Search, the mechanism is similar: crawler access is a prerequisite, but being crawled is not sufficient for citation.
73% of sites have technical barriers: and most predate AI search
An OtterlyAI analysis found 73% of websites have at least one technical barrier preventing AI crawler access. The breakdown: misconfigured robots.txt, CDN-level blocks that catch bot traffic indiscriminately, and JavaScript rendering failures.
The JavaScript problem is the most significant. A Writesonic analysis of 6 AI crawlers found ChatGPT, Claude, and Gemini parse static HTML only. DeepSeek and Grok execute headless JavaScript. Copilot is the only platform that renders the full browser environment. Search Engine Land measured a 9× difference in parsing time between client-side JavaScript pages and equivalent static HTML pages.
If your content is rendered client-side, three of the four dominant AI platforms may not be reading it. Not because of AI-specific configuration gaps: because of the same rendering limitation that has always applied to JavaScript-heavy sites in traditional SEO.
ClaudeBot's crawl-to-referral ratio
One finding stands out for crawl budget allocation. A TechnologyChecker analysis of 4,047 robots.txt files found ClaudeBot operates at a 20,583:1 crawl-to-referral ratio: 20,583 pages crawled for every one referral generated. Google's equivalent ratio is 5:1.
This doesn't mean blocking ClaudeBot is the right call. It means that unlike Google, where crawl budget has a relatively direct relationship to indexing and ranking, AI-crawler crawl budget translates to referrals at a much lower rate. Optimising for traditional search indexing delivers a better return than optimising specifically for AI crawlers.
URL structure has a measurable effect
An Ahrefs study of 1.4 million prompts found descriptive URL slugs produced an 89.78% ChatGPT citation rate versus 81.11% for non-descriptive URLs, an 8.67 percentage point difference. A descriptive slug names the content topic directly: /how-to-write-meta-descriptions or /schema-markup-guide rather than /p/ab9x or /page?id=4521. URL slugs that describe the content topic help AI systems assess relevance at the retrieval stage, before the page is read.
GPTBot: the blocking decision
Zero sites were blocking GPTBot before OpenAI published its documentation. Within one month, approximately 125,000 sites from 12 million analyzed had added a GPTBot block. Blocking GPTBot prevents your content from being used in ChatGPT's training data and search retrieval. Blocking OAI-SearchBot separately prevents ChatGPT Search from citing your content while GPTBot continues for training data. Each crawler is controlled independently.
What the evidence doesn't prove
The 73% figure from OtterlyAI includes a wide range of barrier severity, a partially misconfigured robots.txt and a full CDN block are both counted as "barriers." The real distribution of impact is not reported.
Crawl rate data (59% of sites receiving AI crawler visits in Duda's dataset) doesn't translate directly to citation rates. Being crawled is necessary but nowhere near sufficient. The ceiling is set by retrieval-layer eligibility, which for most AI search platforms means traditional search position.
How to audit and fix AI crawlability issues
19 platform-official statements plus 16 corroborating sources back this finding: high confidence across google-aio. Act on this now: it's one of the better-evidenced tactics in the database. Unlike content tactics, this is binary: either your technical setup passes the bar or it doesn't. Audit first, fix second. Technical debt here blocks every downstream optimisation.
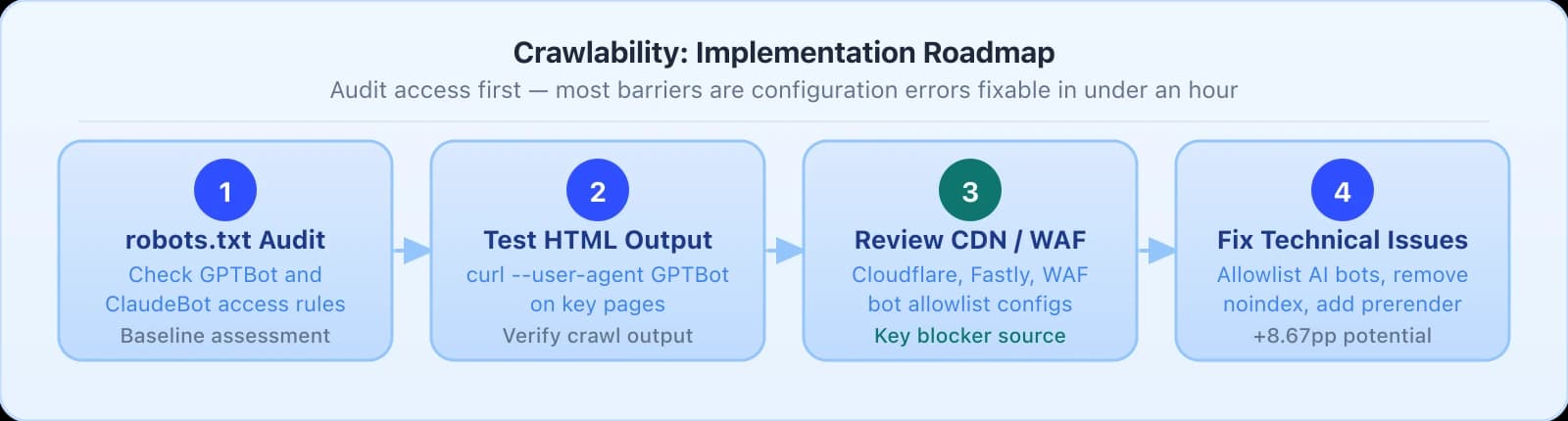
Implementation
- 1Audit your robots.txt for AI crawler access: verify that GPTBot (OpenAI), OAI-SearchBot (OpenAI Search), ClaudeBot (Anthropic), Google-Extended (Google AI), PerplexityBot, and Bingbot (Microsoft) are each explicitly allowlisted. Each requires separate allowlisting: allowing one has no effect on the others.
- 2Test pages for server-side HTML availability: use curl to fetch your highest-traffic URLs and verify that main content is present in the raw HTML response without JavaScript execution. Five of seven major AI crawlers cannot render JavaScript.
- 3Check CDN and WAF rules for bot-blocking patterns: rules targeting any User-Agent containing "bot" or "crawler" can inadvertently block legitimate AI crawlers alongside malicious traffic.
- 4Fix broken canonical tags and redirect chains on high-traffic pages: AI crawlers operate with limited crawl budgets, and URL resolution errors consume crawl capacity without returning readable content.
Frequently asked questions
- Does ensuring AI crawlability and indexing help you get cited in AI search results?
- Yes: high confidence across 35 sources (score: 18.0/35). 19 are platform-official: the strongest possible signal. No contradicting evidence found.
- Does ensuring AI crawlability and indexing work for ChatGPT, Perplexity, and Google AI Overviews?
- The research covers google-aio. Platform-official guidance exists for this tactic: the strongest possible confirmation. Results may vary by platform as AI systems evolve: verify against current documentation before acting.
- How was the evidence collected?
- The 35 sources use official platform documentation and observational studies and controlled experiments. 4 sources are academic or peer-reviewed. All sources are listed with direct links in the Sources section below.
- Should I prioritise Ensure AI crawlability and indexing over other GEO tactics?
- Given the high confidence rating and platform-official backing, yes: this is one of the better-evidenced tactics in the database. Unlike content tactics, this is binary: either your technical setup passes the bar or it doesn't. Audit first, fix second. Technical debt here blocks every downstream optimisation.
How this score is calculated
Each source is weighted by tier, independence, and how recent it is. Click to see the full breakdown and how the score has changed over time.
Sources
- [1]AI features in Google Search: your questions, answeredGoogle Search CentralPlatform official· retrieved Apr 6, 2026
- [2]Google-Agent crawler documentation (user-triggered fetchers)GooglePlatform official· retrieved Apr 11, 2026
- [3]Optimizing Your Content for Inclusion in AI Search AnswersMicrosoft· Platform official· retrieved Apr 26, 2026
- [4]Search Off the Record Episode 111Google Search Central· Platform official· retrieved Jun 22, 2026
- [5]Publishers and Developers FAQOpenAI· Platform official· retrieved Apr 23, 2026
- [6]Google upgrades AI Mode in the Chrome browserGoogle· Platform official· retrieved Apr 22, 2026
- [7]Authenticate requests with Web Bot Auth (experimental)Google· Platform official· retrieved May 15, 2026
- [8]Radar 2025 Year in ReviewCloudflare· Platform official· retrieved Apr 23, 2026
- [9]Succeeding in AI SearchGoogle Search Central· Platform official· retrieved Apr 17, 2026
- [10]Perplexity crawler documentationPerplexity AI· Platform official· retrieved Apr 17, 2026
- [11]ChatGPT SearchOpenAI· Platform official· retrieved Apr 17, 2026
- [12]2026 Q2 AI Traffic ReportAdobe· Platform official
- [13]Understanding Core Web Vitals and Google search resultsGoogle· Platform official· retrieved Apr 26, 2026
- [14]Overview of OpenAI CrawlersOpenAI· Platform official· retrieved Apr 26, 2026
- [15]Perplexity CrawlersPerplexity AI· Platform official· retrieved Apr 26, 2026
- [16]Does Anthropic crawl data from the web, and how can site owners block the crawler?Anthropic· Platform official· retrieved Apr 26, 2026
- [17]ChatGPT Search for Enterprise and EduOpenAI· Platform official· retrieved Apr 26, 2026
- [18]Data, privacy, and security for web search in Microsoft 365 CopilotMicrosoft· Platform official· retrieved Apr 26, 2026
- [19]Announcing new options for webmasters to control usage of their content in Bing ChatMicrosoft Bing· Platform official· retrieved Apr 26, 2026
- [20]
- [21]AI Crawler Analysis: 858,457 Sites, 68.9 Million VisitsDuda· Independent study
- [22]68 Million AI Crawler Visits: AI Crawling AnalysisDuda· Independent study
- [23]Your Crawl Budget Is Costing You Revenue in the AI Search EraSearch Engine Land· Academic research
- [24]Answer Engine Optimization: Strategic Content Architecture for AI-Powered Discovery and CitationLeading Minds / Academic Thesis· Academic research
- [25]llms.txt and AI Visibility: Results from OtterlyAI 90-Day ExperimentOtterlyAI· Independent study
- [26]We Analysed robots.txt Across Cloudflare's Network — Q1 2026 AI Crawler ReportTechnologyChecker· Independent study
- [27]AI Bots and robots.txt — HTTP Archive Analysis of 12 Million Websitespaulcalvano.com· Independent study
- [28]2025 AI Visibility Report: How LLMs Choose What Sources to MentionThe Digital Bloom· Independent study
- [29]AI Search and JavaScript Rendering – How Client-Side Rendering Causes Visibility ProblemsGSQi (Glenn Gabe)· Independent study
- [30]The AI Citation Economy: What 1+ Million Data Points RevealOtterlyAI· Independent study
- [31]ChatGPT 5.3 / 5.4 Citation and Crawl AnalysisResoneoIndustry report
- [32]Why ChatGPT Cites One Page Over Another (Study of 1.4M Prompts)Ahrefs· Industry report
- [33]AI Crawler Study: What 60+ Tests Across 6 LLMs RevealWritesonic· Industry report
- [34]AI Citations, User Locations, & Query ContextYext· Industry report
- [35]Manipulating Large Language Models to Increase Product VisibilityarXiv· Academic research
Related tactics
Yes — schema markup improves AI search entity understanding. JSON-LD Article, FAQ, and HowTo data helps AI systems identify entities and relationships on your page.
No — llms.txt has no measurable LLM citation impact. A 129,000-domain study found zero correlation with ChatGPT citations; treat as hygiene, not a ranking signal.
Yes — Core Web Vitals improve AI search eligibility via Google signals. Fast-loading pages with strong performance scores are preferred by Google AI Overviews.
Yes — server-side rendering is required for LLM crawlability. 5 of 7 AI crawlers cannot render JavaScript; ChatGPT hits 34.82% 404 errors per crawl on JS-only pages.