Does server-side rendering improve AI crawler access and citations?
Key findings
- 15 of 7 major AI crawlers cannot render JavaScript: GPTBot, ClaudeBot, Meta, ByteDance, and PerplexityBot parse static HTML only (Vercel, crawl log analysis, April 2026)
- 2ChatGPT encounters 34.82% 404 error rates on JavaScript-only pages; same content served as SSR retrieved successfully (Vercel; GSQi controlled experiment)
- 3Client-side JavaScript pages take 9× longer for AI crawlers to parse than static HTML: directly reducing crawl depth on JS-heavy sites (Search Engine Land)
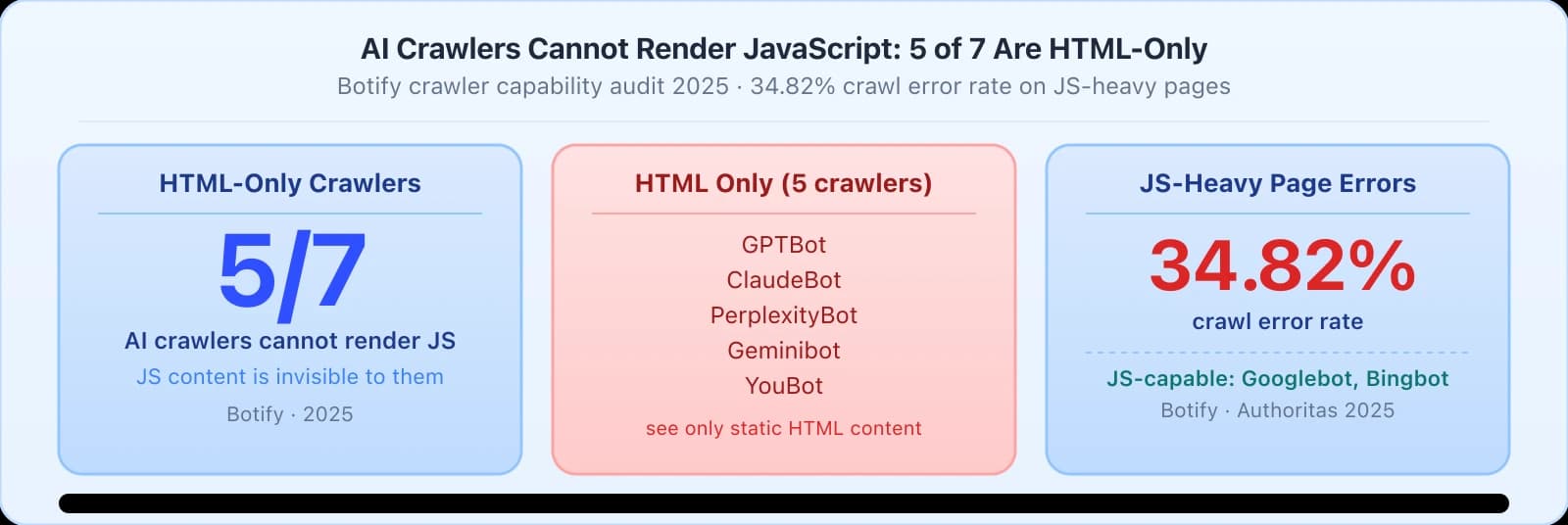
Five of the seven major AI crawler platforms cannot execute JavaScript. OpenAI, Anthropic, Meta, ByteDance, and Perplexity all parse static HTML only. If your site renders key content via client-side JavaScript, those five platforms may not be reading your content at all. A Vercel analysis of crawl logs found ChatGPT encounters 34.82% 404 errors per crawl on JavaScript-only pages, while successfully retrieving the same content when served as static HTML.
What is server-side rendering for AI search crawlers?
Server-side rendering (SSR) is a web architecture approach where the server sends fully-rendered HTML to the browser, rather than sending a JavaScript bundle the browser must execute to generate page content. Static site generation (SSG) and incremental static regeneration (ISR) are related patterns that pre-render pages at build time or on a revalidation schedule. All three approaches produce HTML that AI crawlers can read without JavaScript execution.
The distinction matters for AI search because AI crawler bots do not operate like browsers. They retrieve HTML and parse it: they do not run JavaScript, load resources, or trigger client-side rendering. A page that appears complete in a browser may return a nearly empty HTML document to an AI crawler. An AI system that cannot read your content cannot cite it, regardless of content quality. The crawlability gap is not exotic; it is the same JavaScript rendering problem that has always limited Google indexing for JavaScript-heavy sites, now affecting a broader set of platforms with fewer resources to spend rendering each page.
4 sources reviewed · Medium confidence (9.2/35)
Does server-side rendering improve AI crawler access and citations?
Yes: but the fix is simpler than most teams expect.
The core finding from Vercel's April 2026 analysis of AI crawl logs: five of seven major AI crawlers parse static HTML only. OpenAI (GPTBot and OAI-SearchBot), Anthropic (ClaudeBot), Meta, ByteDance (Bytespider), and PerplexityBot cannot render JavaScript. Only Google's crawlers and Applebot possess full JavaScript rendering capabilities.
For pages that rely on client-side rendering: React SPAs, Angular apps, Vue applications: three of the four dominant AI platforms may not be reading the content at all.
ChatGPT's 34.82% error rate on JavaScript pages
The Vercel finding is specific: ChatGPT encounters 34.82% 404 errors per crawl on JavaScript-only pages: errors that don't occur when the same content is served as static HTML. ClaudeBot hits 34.16% error rates under the same conditions.
A GSQi controlled experiment demonstrated this directly: ChatGPT reported it "could not read the content of the page because it relied on JavaScript-based rendering," then successfully retrieved the server-side rendered version of the identical page.
A Search Engine Land observational study measured the crawl time difference: pages relying on client-side JavaScript rendering take 9× longer for AI crawlers to parse than static HTML equivalents. For crawlers operating with limited crawl budgets, that time cost translates directly into reduced crawl depth.
The 73% barrier problem
An OtterlyAI analysis found that 73% of websites have at least one technical barrier blocking AI crawler access. JavaScript rendering failures are the largest category, not misconfigured robots.txt, not CDN blocks, but the structural rendering gap. The barrier isn't intentional. It's the default state of modern JavaScript-heavy web development.
SSR, SSG, ISR: which to use
For AI crawlability, any of the three server-rendering approaches is sufficient. SSG (pre-rendered at build time) is the most crawlable but requires rebuild for content updates. ISR (pre-rendered on a revalidation schedule) balances freshness and crawlability. SSR (rendered on each request) serves fresh HTML but at higher server cost.
The key principle: ensure your main content, metadata, and navigation are present in the HTML a crawler receives without executing any JavaScript. Enhancement features: interactive UI, personalisation, live data updates: can remain client-side. Core content cannot.
Allow AI crawlers in robots.txt
SSR alone is insufficient if your robots.txt blocks AI crawlers. The bots to allowlist explicitly: PerplexityBot, GPTBot, OAI-SearchBot (OpenAI Search), ClaudeBot (Anthropic), Google-Extended (Google AI training), Bingbot (Microsoft). Each crawler is controlled independently: allowing GPTBot has no effect on ClaudeBot.
What the evidence doesn't prove
The Vercel and GSQi findings are crawl-access data, not citation rate data. Being crawlable is a prerequisite for being cited but doesn't guarantee it. A site with perfect server-side rendering and no other GEO signals will not automatically earn AI citations.
The Search Engine Land 9× parsing time figure is an observational measurement. Sites vary significantly in JavaScript bundle complexity, and the actual time penalty depends heavily on implementation details.
How to implement SSR, SSG, and ISR for AI crawlability
4 independent sources back this finding: medium confidence across chatgpt, perplexity, gemini. Treat this as promising but not yet proven: run a small experiment before broad rollout. Unlike content tactics, this is binary: either your technical setup passes the bar or it doesn't. Audit first, fix second. Technical debt here blocks every downstream optimisation.

Implementation
- 1Verify what AI crawlers actually receive: use curl to fetch your highest-traffic URLs and check whether main content is present in the raw HTML without JavaScript execution. Five of seven major AI crawlers cannot render JavaScript; client-side rendered content is invisible to them.
- 2Implement static HTML rendering for all content pages: use SSG (pre-rendered at build time), ISR (pre-rendered on a revalidation schedule), or SSR (rendered on each request) depending on your update frequency. Any approach that sends HTML to crawlers without requiring JavaScript is sufficient.
- 3Allowlist AI crawlers in robots.txt alongside SSR: GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, Google-Extended, and Bingbot each require separate allowlisting. SSR alone is insufficient if robots.txt blocks crawler access.
- 4Keep interactive UI enhancements client-side while serving core content and metadata server-rendered: product descriptions, article content, headings, and metadata must be in the initial HTML. Filters, tabs, and personalisation can remain client-side without affecting AI crawlability.
⚠Evidence is medium: treat these steps as experimental, not established practice. Run a small test before broad rollout.
Frequently asked questions
- Does using server-side rendering for AI crawlers help you get cited in AI search results?
- Yes: medium confidence across 4 sources (score: 9.2/35). No contradicting evidence found.
- Does using server-side rendering for AI crawlers work for ChatGPT, Perplexity, and Google AI Overviews?
- The research covers chatgpt, perplexity, gemini. No platform-official statement exists yet: the evidence comes from academic research and independent practitioner experiments. Results may vary by platform as AI systems evolve: verify against current documentation before acting.
- How was the evidence collected?
- The 4 sources use observational studies and controlled experiments. 1 source is academic or peer-reviewed. All sources are listed with direct links in the Sources section below.
- Should I prioritise Use server-side rendering for AI crawlers over other GEO tactics?
- With a medium confidence rating, this should be treated as secondary to higher-confidence tactics. Unlike content tactics, this is binary: either your technical setup passes the bar or it doesn't. Audit first, fix second. Technical debt here blocks every downstream optimisation.
How this score is calculated
Each source is weighted by tier, independence, and how recent it is. Click to see the full breakdown and how the score has changed over time.
Sources
- [1]Your Crawl Budget Is Costing You Revenue in the AI Search EraSearch Engine Land· Academic research
- [2]AI Search and JavaScript Rendering – How Client-Side Rendering Causes Visibility ProblemsGSQi (Glenn Gabe)· Independent study
- [3]The AI Citation Economy: What 1+ Million Data Points RevealOtterlyAI· Independent study
- [4]The Rise of the AI CrawlerVercel· Industry report
Related tactics
Yes — crawlability is the foundational requirement for AI search. Content must be indexed; no AI citation is possible without this baseline technical prerequisite.
Yes — schema markup improves AI search entity understanding. JSON-LD Article, FAQ, and HowTo data helps AI systems identify entities and relationships on your page.
No — llms.txt has no measurable LLM citation impact. A 129,000-domain study found zero correlation with ChatGPT citations; treat as hygiene, not a ranking signal.
Yes — Core Web Vitals improve AI search eligibility via Google signals. Fast-loading pages with strong performance scores are preferred by Google AI Overviews.